Why does this matter?
The world still faces a difficult medical imaging problem: skin lesions often look similar, but the diagnosis behind them can be very different.
Dermoscopic images can hide important cues behind hair, shadows, and texture noise. At the same time, class imbalance makes some lesion types harder to recognize than others, which raises the risk of misclassification.
Learning the right visual cues is hard when lesions overlap in appearance, data is unevenly distributed, and the model must remain reliable in a clinical setting.
Visual similarity
Many lesion types share overlapping color, shape, and texture patterns.
Uneven data
Rare lesions are easy to overlook when the training set is not balanced.
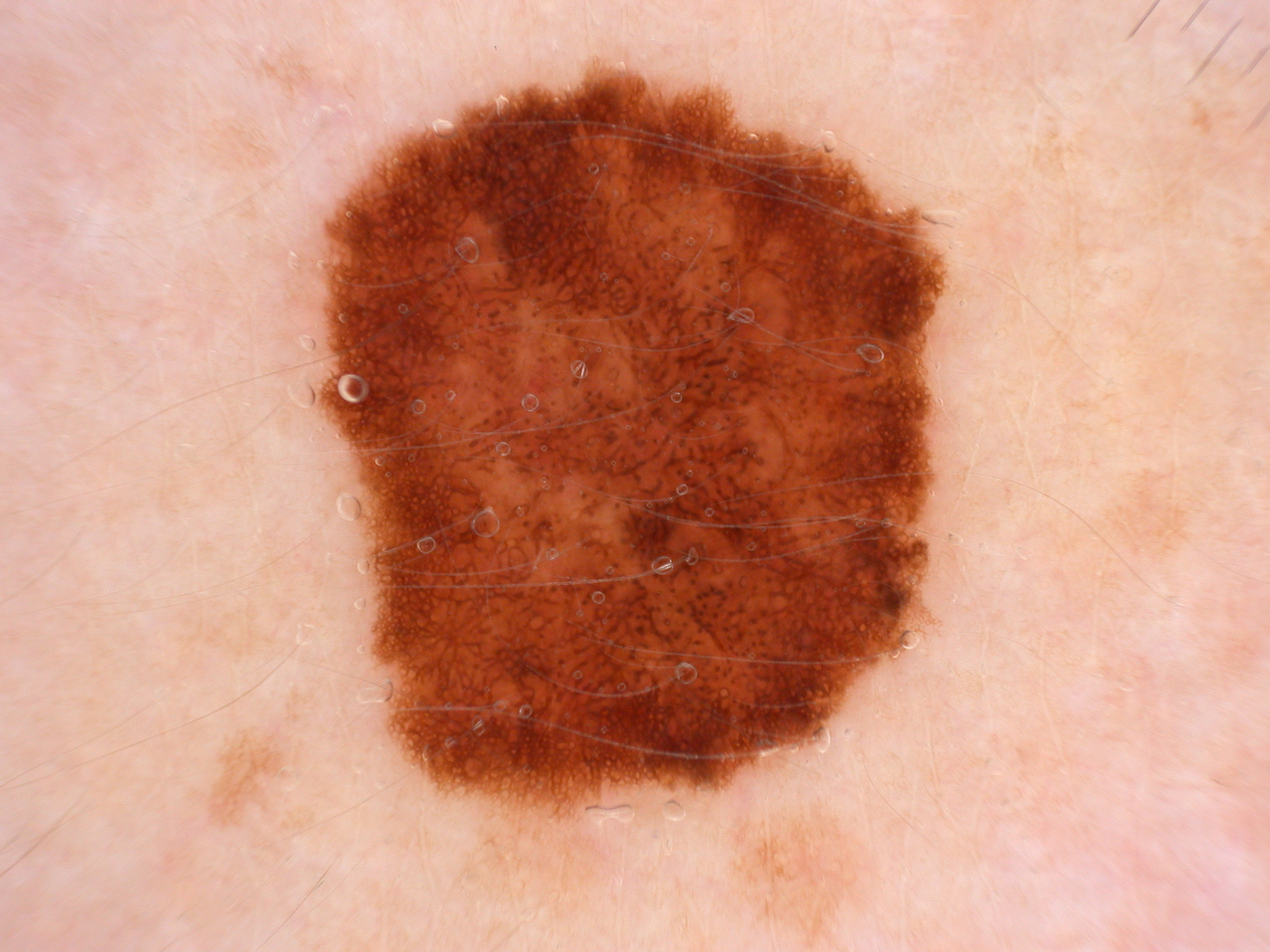
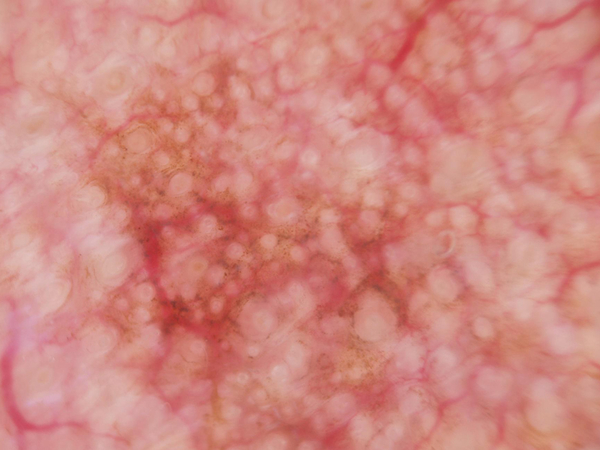
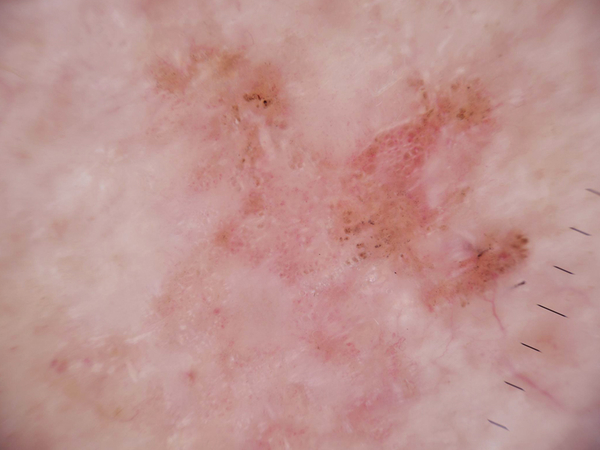
Even different lesion types can appear deceptively close, so the model has to learn subtle discriminative cues.
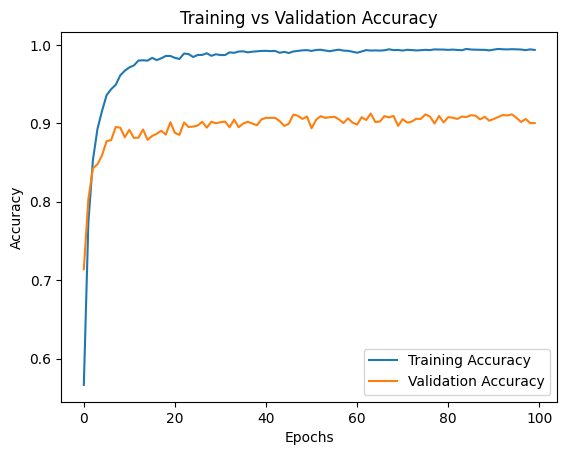
DenseNet201 — 91.91% Test Accuracy
Training vs Validation Accuracy
Confusion Matrix
Sample Predictions

VGG16 — 90.84% Test Accuracy
Training vs Validation Accuracy
Confusion Matrix
Sample Predictions

VGG19 — 90.44% Test Accuracy
Training vs Validation Accuracy
Confusion Matrix
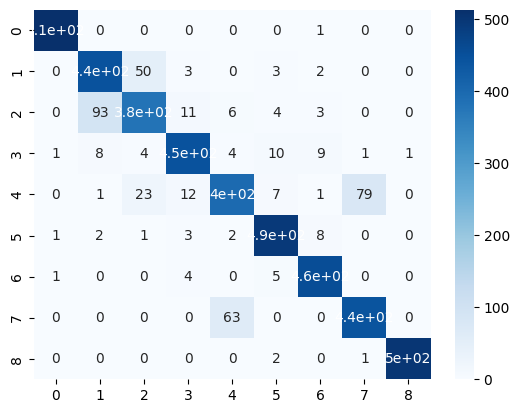
Sample Predictions

Token Stacking + Multi-head Attention — Results
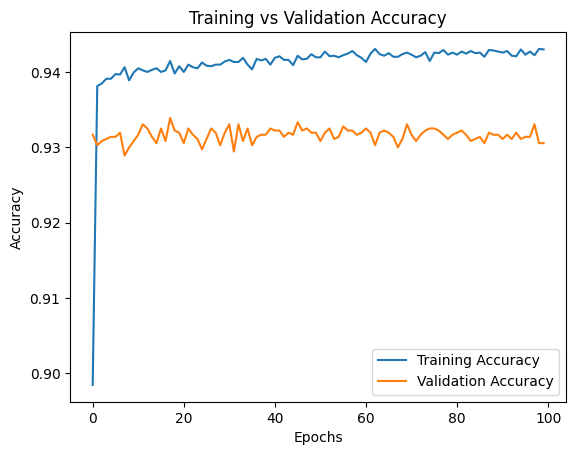
Training vs Validation Accuracy
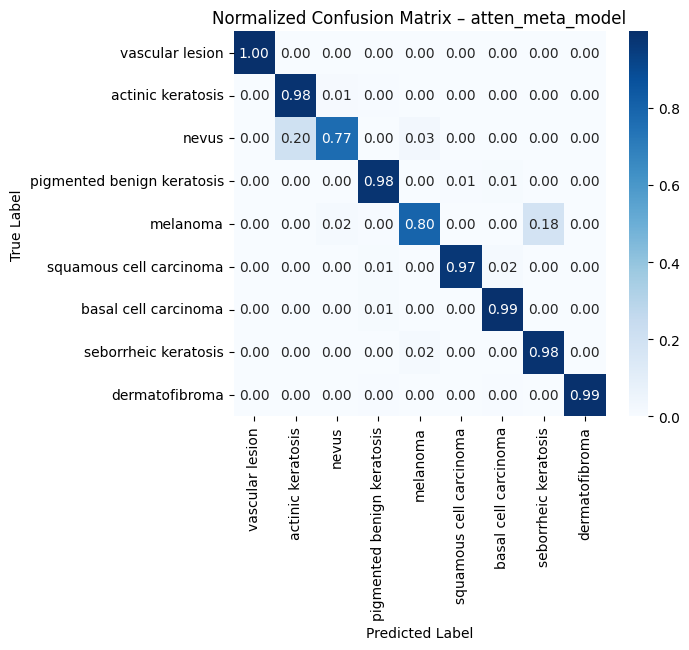
Normalized Confusion Matrix
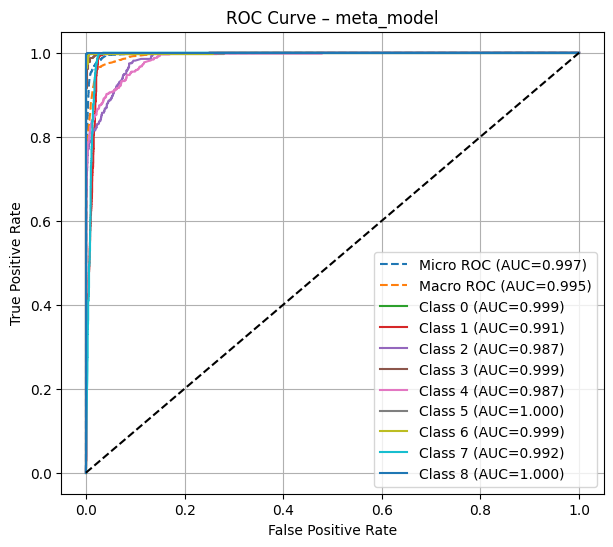
ROC Curves (Micro AUC 0.997)
Can the model explain itself?
We applied Grad-CAM to verify that our trained model focuses on clinically relevant skin lesion features — not background noise or artefacts.
Gradient-weighted Class Activation Maps — heatmap overlays on test images
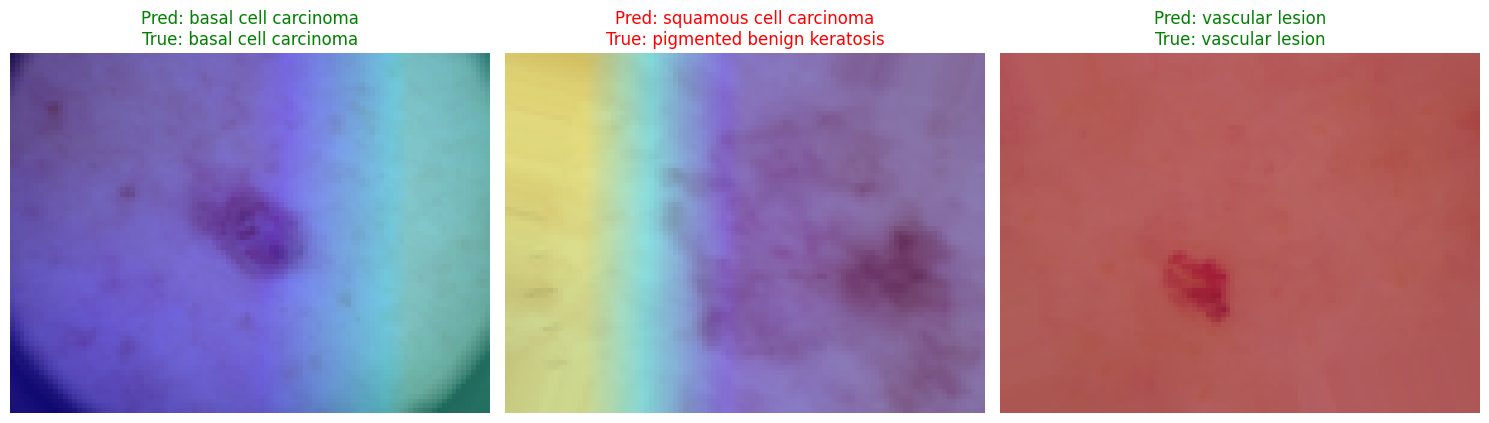
Warmer regions indicate higher gradient activation. The model consistently highlights the lesion boundary and pigmentation texture — not surrounding healthy skin.